
Was die Benchmarks zu GPT-5.4 über die Zukunft der Büroarbeit verraten
Die Diskussion über künstliche Intelligenz konzentrierte sich lange Zeit auf eine vergleichsweise enge Frage: Wie gut können Sprachmodelle Texte schreiben, Fragen beantworten oder programmieren? Mit der Veröffentlichung von GPT-5.4 verschiebt sich diese Perspektive deutlich. Erstmals rückt ein anderer Leistungsbereich in den Mittelpunkt der Analyse – die Fähigkeit von KI-Systemen, reale Computerarbeit auszuführen.
Damit verändert sich auch der Maßstab, an dem Fortschritte in der KI-Forschung bewertet werden müssen. Entscheidend ist nicht mehr nur, ob ein Modell „intelligent“ erscheint, sondern ob es in der Lage ist, tatsächliche Arbeitsprozesse zu übernehmen.
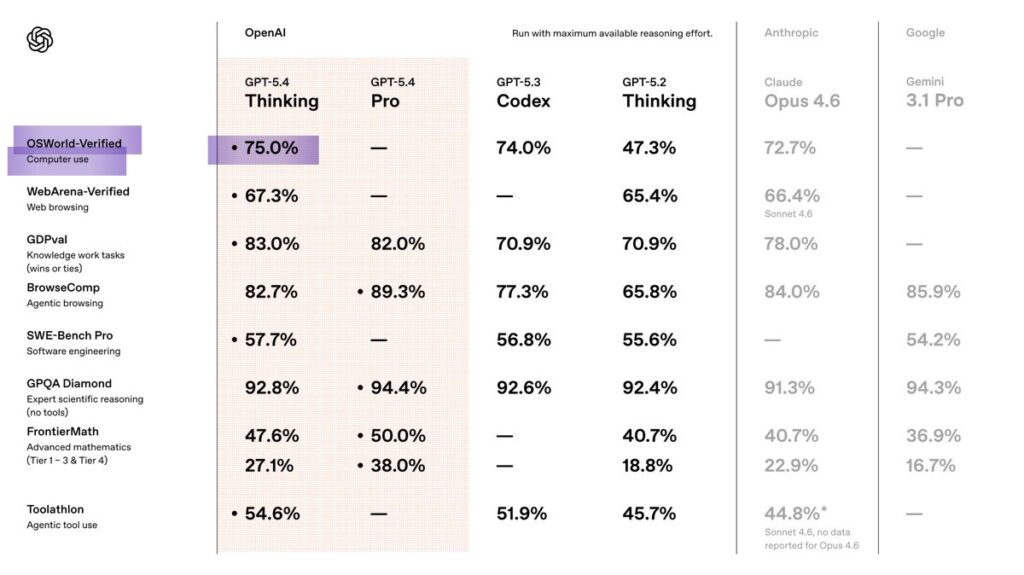
Ein besonders aufschlussreicher Indikator für diese Entwicklung ist der Benchmark OSWorld-Verified. Dieser Test misst die Fähigkeit eines KI-Systems, einen realen Computer zu bedienen. Anders als klassische Benchmarks basiert er nicht auf isolierten Fragen oder Aufgaben, sondern auf vollständigen digitalen Arbeitsabläufen. Das zugrunde liegende Benchmark-System umfasst mehrere hundert Aufgaben, bei denen ein Modell in einer realistischen Betriebssystemumgebung mit Desktop-Programmen, Dateisystemen und Webanwendungen interagieren muss. Die Aufgaben reichen von der Bearbeitung von Dokumenten über Datenanalyse bis hin zu mehrstufigen Workflows, die mehrere Programme miteinander verbinden. Insgesamt umfasst der Benchmark rund 369 reale Computeraufgaben, die aus Tutorials, Forenbeiträgen und praktischen Nutzungsszenarien abgeleitet wurden. Die KI erhält lediglich eine Aufgabenbeschreibung und muss anschließend selbstständig Aktionen wie Mausklicks, Tastatureingaben oder Programmwechsel durchführen.
Diese Art von Benchmark stellt einen fundamentalen methodischen Fortschritt dar. Klassische Evaluationsmethoden für KI konzentrieren sich meist auf eng definierte Kompetenzen – etwa mathematische Probleme, Wissensfragen oder Programmieraufgaben. Solche Tests können zwar Aussagen über spezifische Fähigkeiten treffen, sie erfassen jedoch nicht den Charakter moderner Wissensarbeit. Büroarbeit besteht in der Praxis selten aus einzelnen isolierten Aufgaben. Sie ist vielmehr durch komplexe Handlungsketten geprägt: Informationen recherchieren, Daten analysieren, Ergebnisse dokumentieren und anschließend kommunizieren. Der OSWorld-Benchmark versucht genau diese Art von Handlungsketten zu messen, indem er Modelle in eine reale Softwareumgebung versetzt und sie dort eigenständig agieren lässt.
Die Ergebnisse, die mit der Veröffentlichung von GPT-5.4 präsentiert wurden, sind in diesem Kontext bemerkenswert. Das Modell erreicht auf OSWorld-Verified eine Erfolgsrate von etwa 75 Prozent und liegt damit leicht über der gemessenen durchschnittlichen menschlichen Erfolgsrate von rund 72 Prozent. Gleichzeitig stellt dies einen massiven Fortschritt gegenüber früheren Modellen dar: GPT-5.2 erreichte in derselben Evaluation lediglich etwa 47 Prozent.
Diese Zahlen sind nicht nur statistisch interessant, sondern haben unmittelbare arbeitsökonomische Bedeutung. Während frühere Generationen von Sprachmodellen vor allem textbasierte Aufgaben unterstützten, demonstriert GPT-5.4 erstmals eine Fähigkeit, die man als „operative digitale Kompetenz“ bezeichnen könnte. Das Modell kann Software bedienen, Dateien organisieren, Dokumente erstellen und Daten zwischen Anwendungen übertragen. Genau diese Tätigkeiten bilden jedoch den Kern vieler Wissensberufe.In ökonomischer Perspektive wird damit eine neue Phase der Automatisierung sichtbar. Historisch betrachtet lassen sich drei große Wellen technologischer Produktivitätssteigerung unterscheiden. Die Industrialisierung automatisierte körperliche Arbeit. Die Computerisierung automatisierte Berechnung und Datenverarbeitung. Die aktuelle Entwicklung automatisiert zunehmend digitale Routinearbeit – also jene Tätigkeiten, die Menschen in Softwareumgebungen ausführen. Die Fähigkeit eines KI-Systems, einen Computer ähnlich wie ein Mensch zu bedienen, stellt deshalb eine entscheidende Schwelle dar. Sobald ein Modell Programme bedienen kann, ist es prinzipiell in der Lage, viele Aufgaben zu übernehmen, die bislang als typische Büroarbeit galten.
Besonders deutlich wird dies bei datengetriebenen Tätigkeiten. Moderne Organisationen erzeugen enorme Mengen digitaler Informationen, die regelmäßig in Tabellen, Präsentationen oder Berichten verarbeitet werden müssen. In vielen Branchen besteht ein erheblicher Teil der Arbeitszeit aus solchen Transformationsprozessen: Daten werden gesammelt, strukturiert, analysiert und anschließend in kommunikative Formate überführt. Genau diese Tätigkeiten lassen sich vergleichsweise gut in automatisierbare digitale Workflows übersetzen. Entsprechend zeigen erste interne Tests von GPT-5.4, dass das Modell bei Aufgaben des Spreadsheet-Modellings – etwa der Erstellung komplexer Tabellenmodelle – Erfolgsraten von über 80 Prozent erreichen kann.
Der entscheidende Unterschied zu früheren KI-Systemen liegt dabei weniger in einzelnen Fähigkeiten als in der Integration verschiedener Kompetenzen. Moderne Modelle kombinieren Sprachverarbeitung, visuelle Wahrnehmung und Handlungsplanung. Dadurch können sie Bildschirmoberflächen interpretieren, Kontextinformationen auswerten und darauf basierend Aktionen ausführen. In der Forschung wird dieses Paradigma häufig als „agentische KI“ bezeichnet. Gemeint sind Systeme, die nicht nur Antworten generieren, sondern eigenständig Handlungen planen und ausführen können.Aus arbeitssoziologischer Perspektive hat diese Entwicklung potenziell weitreichende Konsequenzen. Viele Tätigkeiten in Verwaltung, Finanzwesen oder Projektmanagement sind stark softwarezentriert. Sie bestehen aus einer Sequenz standardisierter Operationen in digitalen Werkzeugen. Wenn KI-Systeme diese Operationen selbstständig ausführen können, verschiebt sich die Rolle des Menschen innerhalb dieser Prozesse. Der Mensch wird zunehmend zum Initiator und Supervisor digitaler Arbeitsabläufe, während die operative Durchführung automatisiert wird.
Dabei ist jedoch zu beachten, dass aktuelle Systeme trotz beeindruckender Leistungswerte noch erhebliche Einschränkungen aufweisen. Studien zeigen beispielsweise, dass KI-Agenten oft deutlich mehr Schritte benötigen als Menschen, um dieselbe Aufgabe zu erledigen. In experimentellen Untersuchungen konnten selbst leistungsstarke Modelle bis zu 2,7-mal mehr Handlungsschritte ausführen als die optimalen menschlichen Lösungswege. Diese Ineffizienz deutet darauf hin, dass KI-Systeme zwar zunehmend in der Lage sind, Aufgaben korrekt zu lösen, jedoch noch nicht über dieselbe operative Eleganz verfügen wie erfahrene menschliche Nutzer.Trotz dieser Einschränkungen markieren die aktuellen Benchmark-Ergebnisse einen strukturellen Wendepunkt.
Während frühere Diskussionen über KI häufig um die Frage kreisten, ob Maschinen menschliche Kreativität oder Intelligenz erreichen können, verschiebt sich die Debatte nun stärker auf die Ebene praktischer Arbeitsfähigkeit. Wenn ein System nicht nur Texte schreibt, sondern tatsächlich Software bedient und komplexe digitale Aufgaben ausführt, nähert es sich funktional der Rolle eines digitalen Mitarbeiters an.Für die Organisation von Wissensarbeit bedeutet dies eine grundlegende Transformation. Die zentrale Kompetenz zukünftiger Arbeitsformen wird weniger in der Bedienung einzelner Programme liegen, sondern vielmehr in der Gestaltung und Steuerung automatisierter Prozesse. Menschen werden zunehmend Aufgaben formulieren, Workflows definieren und Ergebnisse evaluieren, während KI-Systeme die operative Umsetzung übernehmen. In diesem Sinne markiert GPT-5.4 weniger einen isolierten technologischen Fortschritt als vielmehr einen Hinweis auf eine tiefgreifende Verschiebung im Verhältnis zwischen menschlicher Arbeit und digitaler Technologie.
Die entscheidende Frage lautet daher nicht mehr, ob KI bestimmte Tätigkeiten unterstützen kann. Vielmehr stellt sich zunehmend die Frage, welche Rolle dem Menschen in einer Arbeitswelt zukommt, in der Software nicht mehr nur Werkzeug, sondern selbstständig handelnder Akteur ist.